Inference vs. On-Device Training: Making Your Devices Smarter, Not Static
Vedant Wakchaware
April 7, 2026
•
5 min read
Introduction
We are currently living in an era of frozen intelligence. Think about your medical wearable, your fitness tracker, or the smart sensor in your factory. Right now, about 90% of these devices are deployed with fixed logic. This means they are using a snapshot of intelligence that was captured in a giant data center months before the device even reached your hands. When your life changes—your heart rhythm shifts or you start a new exercise—the AI's accuracy collapses because it lacks the ability to learn on the fly.
In this detailed guide, we analyze the two core pillars of the AI lifecycle: Inference and On-Device Training. We will explore why moving beyond simple inference to adaptive learning is the key to the next generation of smart hardware, and how we are finally breaking the power barriers that have held this technology back.
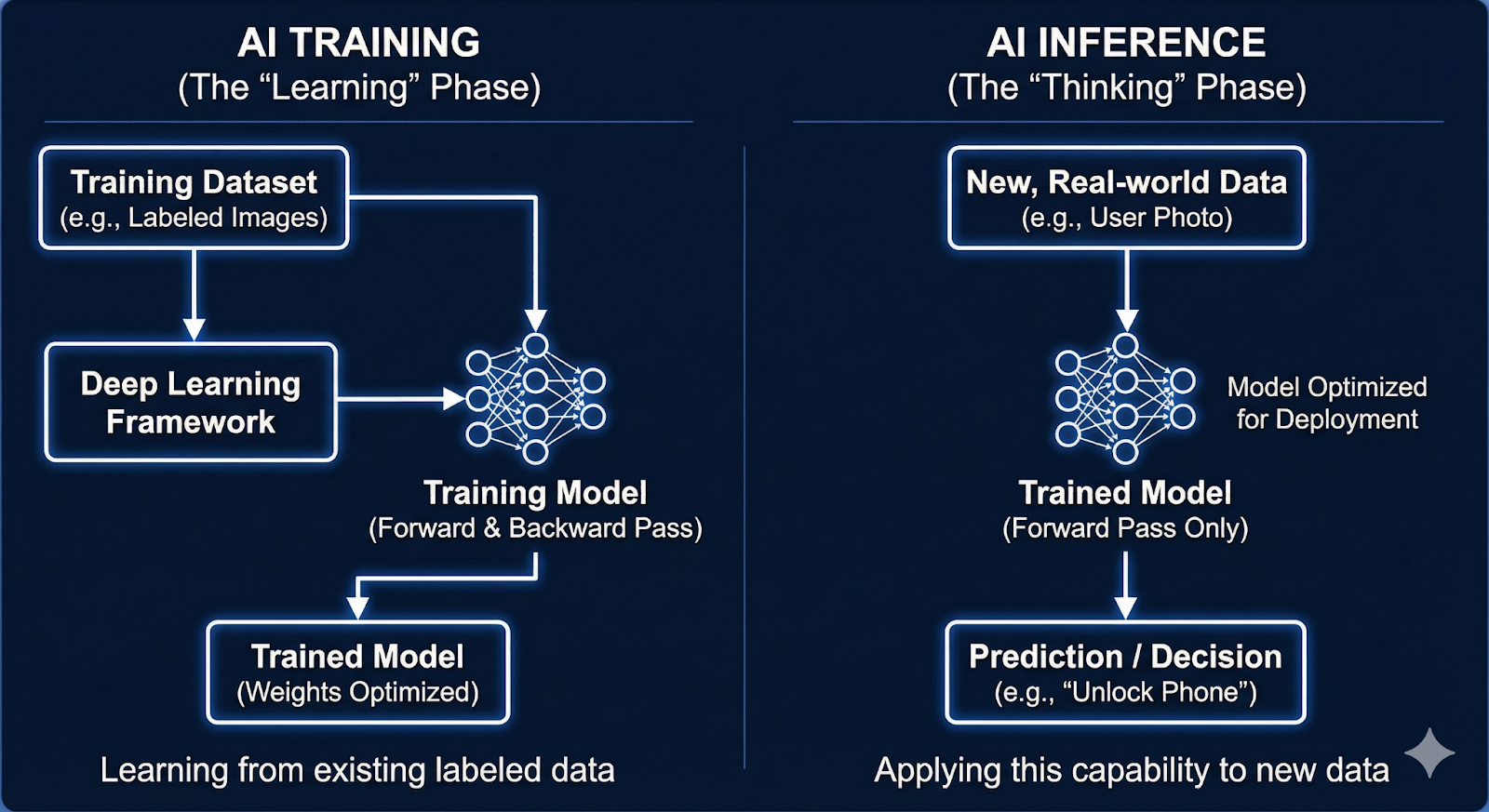
1. What is AI Inference? (The "Thinking" Phase)
Before a device can learn, it has to be able to "think." In the world of Artificial Intelligence, Inference is the stage where a pre-trained model uses what it has already learned to make a real-time decision.
Think of it like a student taking a multiple-choice test using a textbook they have already memorized. During the test, the student isn't learning anything new; they are simply applying their existing knowledge to answer the questions as quickly and accurately as possible.
The Core Components of Inference:
Data Preparation (The Input): The device picks up raw signals from the world—like the movement of your wrist via an accelerometer or the sound of your voice through a microphone.
The Forward Pass: This is the heart of inference. It is a one-way street where data enters the neural network, passes through various layers of mathematical "rules," and flows toward a conclusion.
Fixed Parameters (The Weights): During inference, the "intelligence" of the model is frozen. These settings do not change based on what the device sees.
Quantization: To save battery, the complex math is often "squeezed" (e.g., from 32-bit numbers down to 8-bit integers).
Output Interpretation: The final result, like "Unlocking phone" or "Step detected."
Processes in Inference: Highs and Lows
Where Inference Shines (The Best Parts):
Real-time decision-making: It allows applications to act instantly on incoming data, driving critical use cases like autonomous navigation and medical alerts.
Scalable Environment: Inference environments are often highly scalable, meaning resources can be increased as the user base grows without compromising response times.
Where Inference Struggles (The Not-so-Best Parts):
High Latency: Unoptimized models or weak hardware can lead to slow responses, ruining user experience or causing safety risks in industrial settings.
Performance Dependency: If the model wasn't trained well initially, its performance during inference will be poor, and it cannot fix its own mistakes.
Constant Re-training Needs: Because models "drift" as the real world changes, static inference requires frequent manual updates from the cloud to stay accurate.
2. What is AI Training? (The "Learning" Phase)
If inference is taking the test, AI Training is the process of studying for it. It is the phase where the model actually learns to recognize patterns in data. Traditionally, this required massive data centers, but "On-Device Training" brings this capability directly to your hardware.
The Core Components of the Training Phase:
Data Collection & Pre-processing: The device gathers real-world information and "cleans" it so the model doesn't learn from mistakes or "noise."
The Initial Guess: The model performs a forward pass to see what it thinks the answer is.
Loss Calculation (The Reality Check): The model compares its guess to the truth. If it makes a mistake, it calculates the "error."
The Backward Pass (Backpropagation): The AI moves backwards through its layers to find exactly which mathematical rules caused the mistake.
Weight Optimization: The model updates its internal settings (weights) so it gets the answer right next time.
Processes in Training: Highs and Lows
Where Training Shines (The Best Parts):
Learning Complex Patterns: This is the heart of AI intelligence, helping models understand real-world patterns and solve complex problems by learning from errors.
Scalable Training Environments: Cloud platforms can automatically scale up resources as datasets grow, ensuring efficient processing of billions of data points.
Where Training Struggles (The Not-so-Best Parts):
Data Cleaning Efforts: Building a robust model requires high-quality data. Creating and cleaning these datasets is an exhausting, time-consuming process.
High Costs: Training is expensive in terms of money, time, and energy. It typically requires high-end GPUs and massive power, making it unaffordable for many edge applications.
Optimization Trial-and-Error: Finding the right architecture and parameters is often a tiring process of trial and error that can delay project timelines.
3. AI Inference vs. Training: What’s the Difference?
While they are two halves of the same whole, the technical requirements for Inference and Training represent opposite ends of the hardware spectrum. Understanding these differences is critical for choosing the right silicon architecture.
Purpose & Logic:
Training is the "Teaching Phase." It is an iterative process where a model is presented with massive amounts of data to learn features. It creates the "brain" from scratch.
Inference is the "Action Phase." It is the application of that brain to the real world. When your phone recognizes your face, it is performing inference using a model that was previously trained.
Computational Flow (The Loop):
Training involves a complex bi-directional loop. First, the Forward Pass calculates an output. Then, the Backward Pass (Backpropagation) calculates the "loss" (the error), finds the gradient, and propagates it back through every single neuron to update the weights. This requires significantly more compute cycles.
Inference is a linear, one-way Forward Pass. Data flows from input to output once. There is no error correction or weight updating, making it vastly faster and lighter.
Mathematical Precision:
Training requires high-precision math, typically Floating Point (FP16 or FP32). Because weight updates are often infinitesimally small, low-precision math would result in "rounding errors" that prevent the model from ever actually learning.
Inference thrives on Integer Math (INT8 or INT4). Since the model just needs to distinguish "Cat" from "Dog," it can use highly compressed numbers to save massive amounts of battery power without losing significant accuracy.
Environment & Scalability:
Training has traditionally been a "Cloud-Only" event, requiring banks of high-wattage GPUs.
Inference is the industry standard for the Edge (Smartphones, IoT), optimized for milliwatt consumption.
4. The Edge Dilemma: Bridging the Gap for Battery-Constrained Devices
Up until now, the heavy lifting of AI training has been a luxury reserved for massive data centers with virtually unlimited power and cooling. However, the real world doesn't happen in a server rack. The future of AI is on the "Edge"—in our smartwatches, industrial sensors, smart rings, and remote drones.
These edge devices are inherently "battery-constrained." They operate on incredibly tight energy budgets, often relying on tiny coin-cell batteries or limited solar harvesting. This creates a massive gap in the AI lifecycle: how do we bring the complex, energy-guzzling process of AI learning to devices that only have milliwatts to spare?
If we keep these edge devices limited to simple Inference, they remain static, generic, and eventually become inaccurate as real-world conditions change. But if we rely on the cloud for continuous learning, the energy required to constantly transmit raw data via radio (Wi-Fi, Bluetooth, LTE) will drain their tiny batteries in a matter of hours. Therefore, solving On-Device Training specifically for these low-power devices isn't just a theoretical upgrade—it is the critical missing link required to make hardware truly autonomous, hyper-personalized, and adaptive without constantly needing a charger.
5. Real-World Use Cases: Moving from Static to Adaptive AI
Generic AI models work well in controlled environments, but the real world is messy. For battery-constrained devices where connectivity is limited or bandwidth is expensive, on-device training becomes a critical necessity to prevent "intelligence decay."
Space & On-Orbit Adaptation
CubeSats & Satellites: On-orbit adaptation is nearly impossible today because current AI accelerators (like Jetson Nano) require 5–10W, while a typical CubeSat has only 0.5–2.0W remaining for AI compute. Without on-board training, satellites must downlink massive amounts of raw data (GBs per orbit) to Earth for ground-retraining, leading to stale models and missed insights during critical windows like wildfire eruptions or ISR missions.
Industrial Robotics & Automation
Industrial Robotics: Every industrial robot today runs a frozen brain. While smart when first programmed, they get dumber every hour as real-world conditions drift from the original training data. Fixing this currently requires manual reprogramming or cloud retraining that takes hours to days, causing expensive line stops and false alarms. On-device training allows the robot to adapt in milliseconds to new textures or alignment shifts.
Drones & UAVs
Drones & UAVs: Today's drones carry a frozen model that was smart on the day it was trained. On-device training turns every flight into a learning opportunity. A drone that has flown 100 missions becomes fundamentally better than one that flew only one—not because someone retrained it in the cloud, but because it learned from its own experience on a milliwatt power budget in the field.
Personalized Healthcare & Consumer Tech
Medical Wearables: Most health AI treats all users identically with a population-average model. The moment it meets a real person with unique physiology or heart rhythms, the model is compromised. On-device training allows wearables to adapt to intimate personal data without surrendering that data to remote servers.
Ultra-Low Power Smart Rings: In a device as tiny as a smart ring, every milliwatt counts. Sending raw biometric data to a phone via Bluetooth drains the battery instantly. Local training allows the ring to build a personalized model of the user's stress or sleep cycles while keeping the "power-hungry" radio off.
6. The Strategic Power Play: Why Local Learning is Mathematically Better for Your Battery Constrained Device
A common misconception is that local learning is "too expensive" for a battery. However, in the world of IoT and wearables, the Energy Cost of Radio Transmission (Wi-Fi, LTE, 5G) is the real silent killer.
The Radio Tax: Activating a radio antenna to push raw data to the cloud is a massive energy sink. It involves handshakes, protocol overhead, and maintaining a high-power connection. A single 4G transmission can consume as much energy as millions of local CPU cycles.
The Local Advantage: It is often mathematically cheaper to perform a localized weight update using a micro-power training kernel than it is to keep a radio active long enough to transmit raw data to a server.
The Result: On-device training isn't just about privacy; it's a strategic battery-saving maneuver.
How to Implement Power-Efficient Training:
Event-Triggered Learning: Only initiate a training cycle when model confidence drops below a specific threshold.
Gradient Compression: Reduce the amount of data processed during the backward pass to save clock cycles.
Radio Sleep Cycles: Ensure the radio remains in deep sleep while the NPU (Neural Processing Unit) handles local adaptation.
Actionable Insights:
Actionable Tip: Profile your "Radio-to-Compute" ratio. If transmitting 1KB of data consumes more than 100mJ, your device is a prime candidate for on-device training to save battery.
Case Study (BioSync Wearables): By moving sleep-cycle adaptation from the cloud to the wrist, BioSync extended their device battery life from 3 days to 11 days, simply by reducing the frequency of Bluetooth data syncs.
Key Takeaways:
Radio transmission is often more expensive than local math.
Privacy-first design naturally leads to energy-first results.
7. The Ultimate Challenge: Training for Battery-Constrained Devices
We've mastered milliwatt inference, but doing Training on a Battery-Constrained Device is the industry's "Holy Grail." It requires overcoming three massive technical walls:
The Energy Crisis (The Processor Wall)
Traditional processors are built for linear tasks. Running "Backpropagation" (the calculus of learning) involves heavy matrix math that can drain a tiny wearable battery in minutes.
The Solution: We need Domain-Specific Architectures (DSAs) that "sip" micro-joules per weight update rather than gulping watts.
The Memory Wall (The SRAM Bottleneck)
Inference only needs to remember the current layer of data. Training, however, requires a "short-term memory" (SRAM) to store every gradient and activation during the backward pass. Most tiny chips have less than 1MB of SRAM—a physical brick wall for standard AI.
The Solution: We must use Sparse Learning (only updating some weights) and Memory-Efficient Kernels to learn within these tight confines.
The Precision Dilemma (The Math Wall)
Learning is a game of millimeters. It usually needs high-precision "floating-point" math (FP32) to detect tiny changes. Battery-efficient chips are built for "integer" math (INT8).
The Solution: Bridging this gap—enabling high-precision learning on a micro-power integer budget—is the defining challenge of the next decade.
How to Implement Memory-Efficient Training:
Layer-wise Training: Only update one layer of the neural network at a time to stay under the SRAM limit.
TinyOL (Tiny On-line Learning): Utilize lightweight algorithms designed specifically for microcontrollers (MCUs).
Actionable Insights:
Actionable Tip: Don't try to retrain the whole model. Use Transfer Learning where the head of the model is updated locally while the heavy body remains frozen.
Key Takeaways:
Sparse learning is the key to bypassing 1MB memory limits.
Precision-switching (using INT8 for inference and FP16 for training) is the current industry gold standard.
8. The Future Vision: The Era of Intelligence Autonomy
By the future, the industry will abandon the "Cloud-First" crutch. We are moving toward a future where devices aren't just connected extensions of a central brain, but independent, self-evolving entities. This shift requires moving the entire Backpropagation Loop from the server rack directly onto the milliwatt-scale silicon of the edge.
The Future On-Device Training Roadmap:
Hyper-Personalized Biometrics: Wearables are graduating from "population-average" models. By 2028, your smart ring or watch will use its first 48 hours to learn your unique heart rate variability (HRV) and metabolic triggers. It creates a "Digital Twin" of your biology that stays 100% on-device, offering medical-grade insights without ever exposing your data to a remote server.
Autonomous Fleet Calibration: By 2030, fleets of drones and delivery robots will treat every flight as a training session. By learning from real-world friction, motor wear, and payload imbalances in real-time, a drone with 500 flight hours will be mathematically "wiser" and more stable than a brand-new unit. It adapts its flight control laws on the fly using localized training kernels, thriving where static models crash.
The "Zero-Touch" Industrial Edge: Factory sensors will move beyond simple detection to Autonomous Drift Correction. As hardware ages or environment heat shifts, sensors naturally lose calibration. Instead of requiring a manual technician visit, the 2030 sensor detects its own accuracy decay and initiates a local training cycle to re-align its internal logic, extending hardware lifespan and ROI by over 300%.
FAQ Section
Q: Why can't my current smartwatch "learn" today? A: Most current chips are "Calculators" (Inference-only). Learning (Backpropagation) requires a different level of math and memory that standard low-power chips don't have.
Q: Is on-device training more private? A: Yes. Raw data never leaves the chip. The AI gets smarter locally, and your private life stays private.
Q: Does "learning" drain the battery immediately? A: With traditional chips, yes. However, new architectures like Vellex use specialized kernels that learn using 1/100th the power of a standard CPU.
Q: What is "Model Drift"? A: It's when the world changes but your AI stays the same. On-device training "self-heals" the model so it stays 100% accurate over time.
Q: Can this technology make devices last longer? A: Yes! Self-healing hardware can re-calibrate itself autonomously, extending its physical life from 2 years up to 10 years.
Conclusion
The era of frozen gadgets is coming to an end. For our technology to be truly helpful, it needs to understand us as individuals. By bringing training directly to battery-powered devices, we are moving into a future where our technology grows with us.
Discover the ultimate guide to AI chips in 2025, comparing CPUs, GPUs, TPUs, FPGAs, ASICs, and analog processors. Learn how to boost processing performance, reduce energy costs, and choose the best chip for your AI workloads. Explore cost ranges, efficiency, and real-world applications, and understand why selecting the right AI processor can accelerate training, inference, and large-scale machine learning projects. Perfect for entrepreneurs and tech enthusiasts.
Alternating Current Optimal Power Flow (ACOPF) is a critical tool for managing electricity grids efficiently, balancing generation, transmission, and demand while minimizing costs and emissions. Beyond technical optimization, it drives business value by reducing losses, lowering energy costs, and enhancing reliability. As grids integrate renewables and face growing demand, ACOPF solutions, including AI-driven and high-performance computing approaches are essential for utilities, industrial users, and policymakers seeking resilient, sustainable, and profitable energy systems.
The automotive industry’s shift to electrification, autonomy, and software-defined vehicles demands faster, more efficient computing. Analog compute addresses power, latency, and bandwidth challenges by processing signals near the source, reducing ECU load and cost. Real-world deployments from Tesla, Toyota, Volkswagen, and Waymo show gains in battery life, motor control, and safety. Emerging in-memory and in-sensor compute promise even greater efficiency. In this blog, we talk about how Analog computing is opening new frontiers in automobiles.