The Mechanics of On-Device Training: Hardware and Software Optimizations for the Edge
Vedant Wakchaware
July 7, 2026
•
5 min read
1. Introduction: The Era of On-Device Training
The artificial intelligence landscape is undergoing a massive architectural shift. For years, the industry’s focus has been on perfecting edge inference—compressing pre-trained models so they can "think" and make decisions on our smartphones, smartwatches, and industrial sensors. However, these models remain static. They are snapshots of intelligence frozen in time.
The next evolutionary leap is On-Device Training.
Unlike cloud-based AI, where raw data must be transmitted to massive server farms to update a model's weights, on-device training executes the complex backpropagation loop directly on local hardware. This paradigm shift offers unprecedented benefits: hyper-personalized user experiences, absolute data privacy (since raw data never leaves the device), zero-latency learning, and total offline reliability.
However, executing this continuous learning process on highly resource-constrained hardware is an immense engineering challenge. Let's break down the mechanics, hardware, and software optimizations making adaptive edge AI possible.
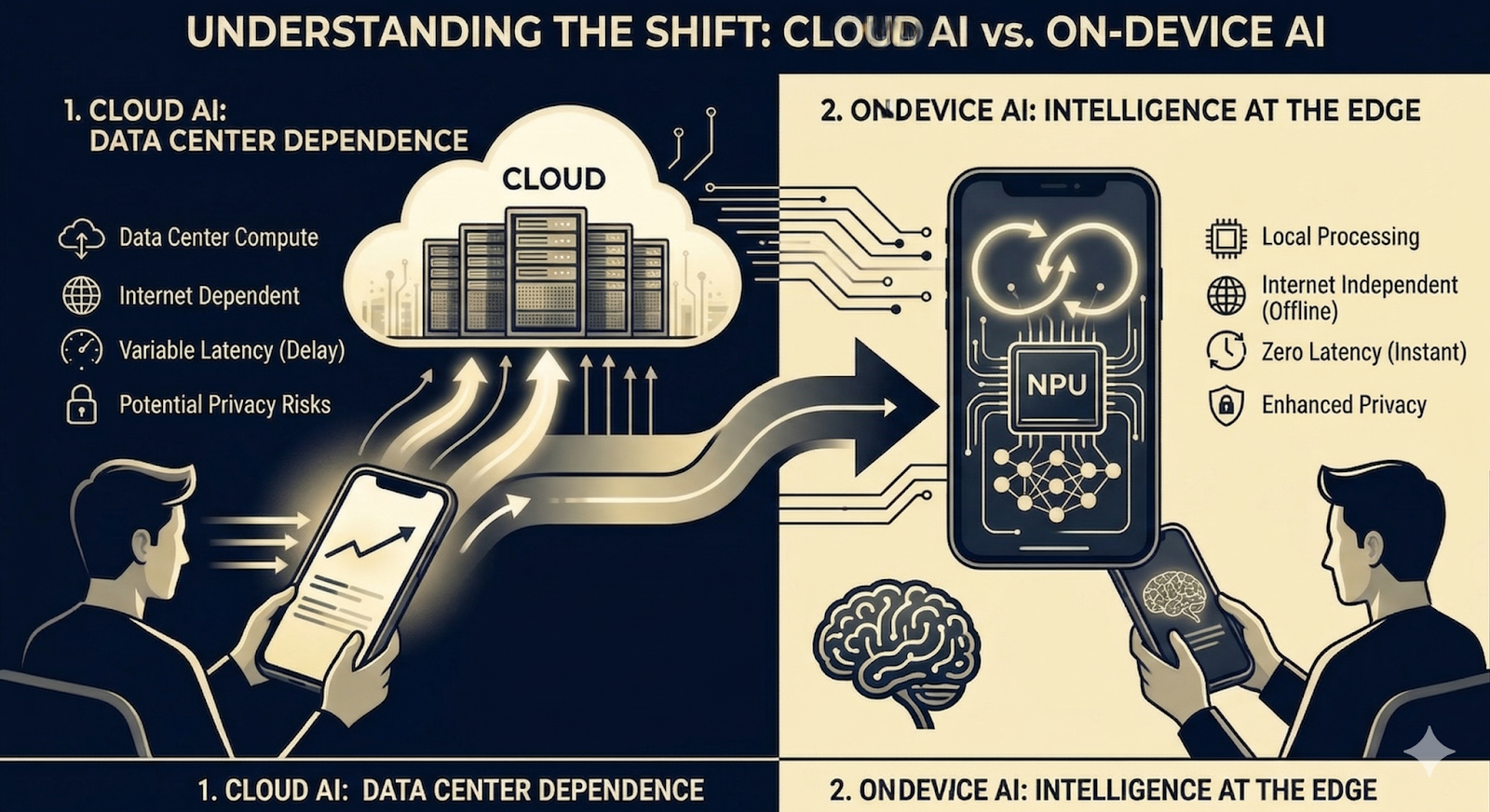
2. Understanding the Shift: Cloud vs. On-Device AI
To fully appreciate the push toward on-device training, it is crucial to understand why moving AI away from the cloud is so valuable. At its core, on-device AI shifts the computational burden from remote data centers directly to the hardware in your hands.
The fundamental distinctions between cloud-based and on-device AI fall into four main categories:
Location of Compute: Cloud-based AI relies on constantly transmitting data to external servers for processing, waiting for the results, and sending them back. On-device AI executes all algorithms locally using the hardware embedded within the device itself.
Privacy and Security: Transmitting raw data over the internet inherently exposes it to potential interception or server-side breaches. On-device processing acts as a natural vault; because your personal data—like voice recordings or health metrics—never leaves the device, exposure to unauthorized access is drastically minimized.
Internet Independence: Cloud architectures completely fail without a robust, continuous internet connection. Conversely, on-device AI operates entirely offline, guaranteeing reliability in remote areas, dead zones, or highly secure industrial environments.
Latency and Speed: Sending data to a server and waiting for a response introduces unavoidable network latency. Local processing enables instantaneous, real-time decision-making, which is an absolute necessity for time-critical applications like autonomous driving or emergency medical monitoring.
While these core benefits have successfully driven the adoption of on-device inference, the industry is now racing to extend these exact same advantages to the much heavier training phase.
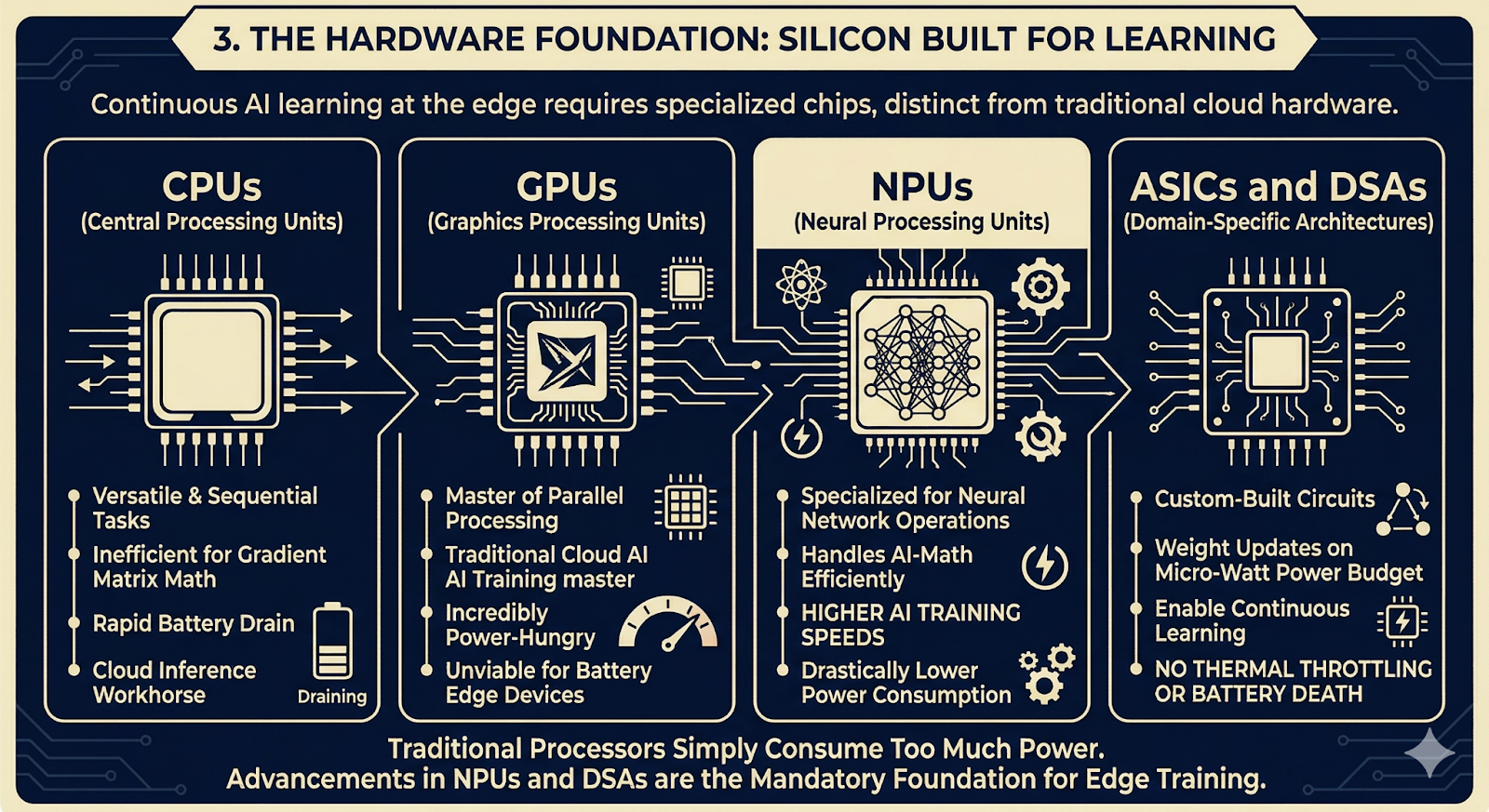
3. The Hardware Foundation: Silicon Built for Learning
To understand how a tiny device can train a neural network, we first have to look at the silicon powering it. The hardware landscape for edge devices is diverse, but not all chips are built for the rigors of continuous learning.
CPUs (Central Processing Units): While versatile and capable of running lightweight AI processes, CPUs execute tasks sequentially. They are inefficient for the heavy, parallel matrix multiplication required to calculate gradients during AI training, leading to rapid battery drain.
GPUs (Graphics Processing Units): GPUs are the masters of parallel processing and the traditional workhorses of cloud AI training. However, they are incredibly power-hungry, making them unviable for battery-constrained edge devices.
NPUs (Neural Processing Units): This is where edge training becomes feasible. NPUs are specialized chips designed explicitly for neural network operations. They handle AI-related math efficiently, at higher speeds, and with drastically lower power consumption.
ASICs and DSAs (Domain-Specific Architectures): Custom-built circuits take efficiency a step further. While inflexible, a custom ASIC designed specifically for sparse learning can perform weight updates on a micro-watt power budget, enabling continuous learning without thermal throttling or battery death.
The reality of the edge is that traditional processors simply consume too much power for continuous learning. Advancements in NPUs and DSAs are the mandatory foundation for moving backpropagation out of the data center.
4. Squeezing "Learning" into Tiny Spaces: Software Optimizations
Even with specialized silicon, edge devices face a massive "Memory Wall." Training requires storing gradients, activations, and historical data—often demanding gigabytes of SRAM, while edge chips usually possess less than a few megabytes.
To squeeze the learning process into these tiny spaces, developers rely on aggressive software optimization techniques.
Quantization: Neural networks typically train using high-precision 32-bit floating-point math (FP32) to capture infinitesimal weight updates. Quantization reduces this precision down to 16-bit or even 8-bit integers (INT8). By training using lower-precision math, the computational load drops dramatically, speeding up the backward pass and saving precious battery cycles.
Pruning & Dense Representations: Not every "neuron" in a network is critical. Pruning involves identifying and removing redundant weights that have little impact on the output. Dense Representation of a deep neural network means a weight matrix where almost all entries are non-zero. Converting a dense representation into Sparse Representation means a weight matrix where, for example, 90% of the values are 0.
Knowledge Distillation & Layer-wise Training: Instead of forcing a tiny edge device to learn everything from scratch, developers use knowledge distillation. This involves a massive, cloud-based "teacher" model passing down its core intelligence to a compressed, highly efficient "student" model on the device. To learn new things locally, devices then use Layer-wise Training (or Transfer Learning). By freezing the vast majority of the network's foundational layers and only retraining the final few layers with fresh local data, the device achieves rapid, memory-efficient adaptation.
Federated Learning : While the techniques above optimize a single device, Federated Learning (FL) connects an entire fleet into a privacy-first collective intelligence. Instead of uploading sensitive, raw user data to the cloud (which drains bandwidth and risks privacy leaks), each device trains its model locally. Devices then extract only the mathematical "lessons learned" (the weight updates) and securely transmit them. A central server aggregates these anonymous updates from millions of devices to forge a continuously evolving, global "master model," which is then beamed back down to the edge.
5. Transformative Applications Powered by On-Device Training
When devices can learn in real-time without pinging a server, the applications transition from merely smart to genuinely autonomous and adaptive.
Healthcare and Wearables: Today's smartwatches use static models based on population averages. With on-device training, a wearable continuously adapts to your unique physiological baseline—learning your specific heart rate variability, sleep anomalies, or gait changes over time. Because this medical profiling happens locally, intimate health data is never exposed to external servers.
Industrial Robotics and Predictive Maintenance: Factory floors are highly dynamic environments. An industrial robot equipped with on-device training doesn't just execute pre-programmed motions; it learns the specific wear-and-tear patterns of its own joints and actuators. It can adapt to new material textures or detect subtle changes in vibrations to predict mechanical failures locally, minimizing costly line stops without needing constant cloud connectivity.
Drones and Remote Exploration: UAVs operating in remote areas (like inspecting pipelines or fighting wildfires) often lack reliable internet. By utilizing on-device training, a drone can adapt its flight control algorithms in real-time to sudden weather changes, unpredictable wind shear, or payload shifts, learning from its environment to remain stable where pre-trained static models would fail.
Smart Agriculture: Remote soil and weather sensors operate on strict power budgets deep in agricultural fields. With local learning, these sensors can adapt their predictive models to micro-climate variations specific to a single acre of land, providing farmers with hyper-localized irrigation triggers without transmitting heavy datasets over rural cellular networks.
Smart Home and IoT Security: Security cameras and voice assistants can train locally to recognize the specific faces of family members or the nuances of household voices. By processing and updating biometric models entirely on the local NPU, the risk of cloud-based data breaches is virtually eliminated.
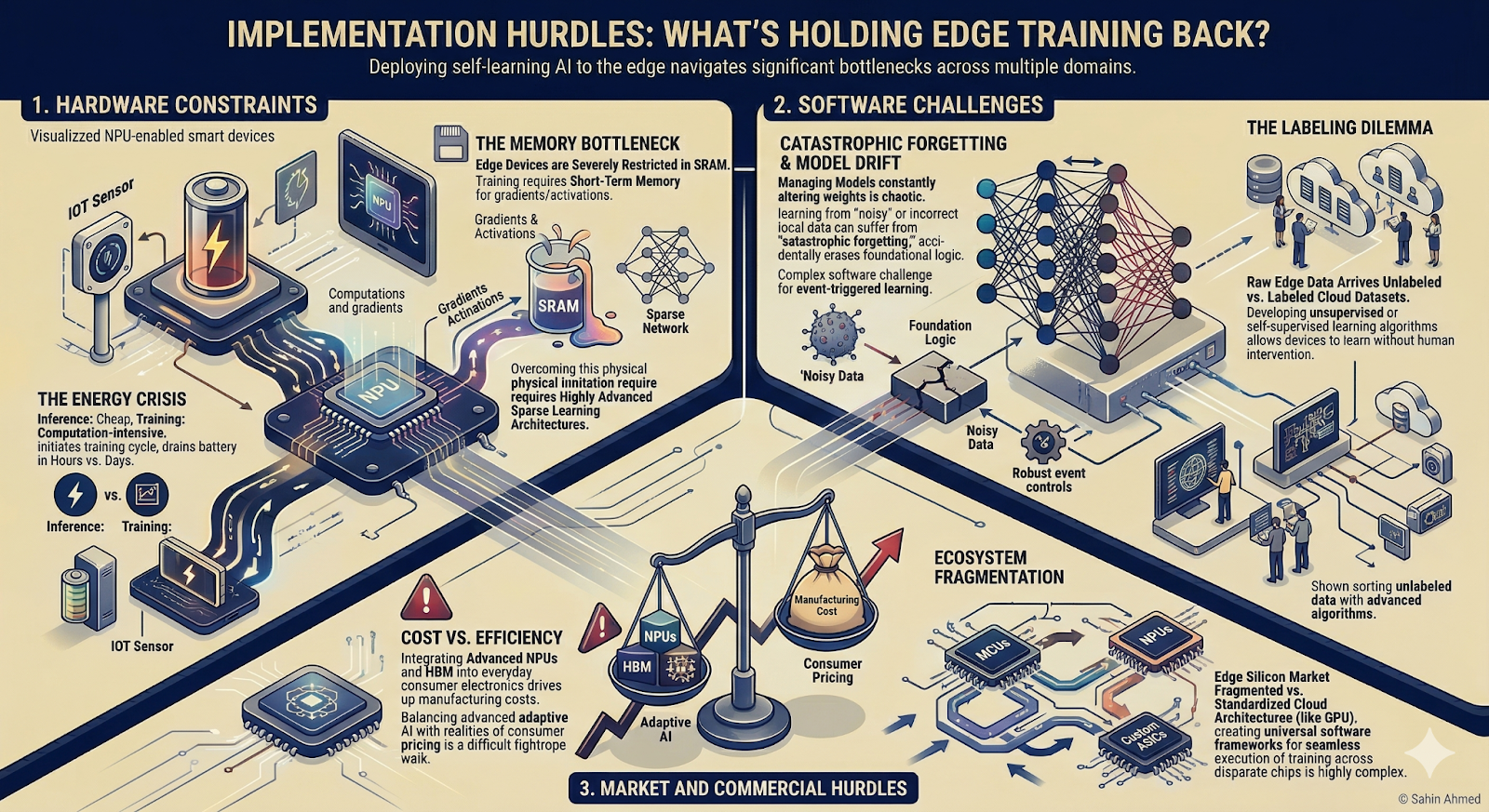
6. Implementation Hurdles: What’s Holding Edge Training Back?
Despite the rapid progress, deploying self-learning AI to the edge involves navigating significant bottlenecks across multiple domains:
Hardware Constraints
The Energy Crisis: While inference is relatively cheap, the backward pass of training requires significantly more computation. If not aggressively optimized, initiating a training cycle on a battery-powered IoT sensor can drain it in hours rather than days.
The Memory Bottleneck: Edge devices are severely restricted in SRAM. Training requires a "short-term memory" to store gradients and activations during the learning phase. Overcoming this physical limitation requires highly advanced, sparse learning architectures.
Software Challenges
Catastrophic Forgetting & Model Drift: Managing models that are constantly altering their own weights in the wild is chaotic. If an on-device model learns from noisy or incorrect local data, it can suffer from catastrophic forgetting, where it accidentally erases its foundational, factory-trained logic. Establishing robust event-triggered learning is a complex software challenge.
The Labeling Dilemma: Cloud AI is traditionally trained on massive datasets neatly labeled by humans. On the edge, real-world data arrives raw and unlabeled. Developing unsupervised or self-supervised learning algorithms that allow the device to learn accurately without human intervention remains a massive hurdle.
Market and Commercial Hurdles
Cost vs. Efficiency: Integrating advanced NPUs and high-bandwidth memory into everyday consumer electronics drives up manufacturing costs. Balancing the desire for advanced, adaptive AI with the realities of consumer hardware pricing is a difficult tightrope walk.
Ecosystem Fragmentation: The edge silicon market is incredibly fragmented. Unlike cloud environments that rely on standardized GPU architectures, the edge is a wild mix of disparate MCUs, NPUs, and custom ASICs. Creating universal software frameworks that can seamlessly execute training across all these different chips is highly complex.
7. Future Prospects: The Autonomous Edge
The trajectory of on-device AI points toward a future completely untethered from the cloud. As chip technology advances—yielding next-generation NPUs with higher efficiency—and machine learning frameworks become increasingly hardware-aware, the barriers to local training will continue to fall.
We are moving past the era of devices that merely infer what is happening around them. The next generation of edge computing will feature fully autonomous, self-evolving entities. These devices will protect our privacy by default, adapt to our changing lives in real-time, and get functionally smarter every single day we use them.
Tokens are the invisible currency of artificial intelligence, and processing them carries a staggering hidden cost. Why does training a frontier model require gigawatt-hours of electricity, while developers face unexpected API bills? Step inside this foundational metric to decode these massive economics. This deep dive breaks down the physical infrastructure required to process trillions of data fragments—from specialized GPU clusters to liquid cooling taxes. Discover the invisible multipliers inflating your usage, and learn comprehensive optimization strategies like smart routing and prompt caching to drastically reduce your AI costs.
While on-device training secures user privacy, it unintentionally traps intelligence, forcing every edge device to learn the exact same lessons from scratch. How do we build a collaborative "hive mind" without exposing raw data to the cloud? The answer is Federated Learning. This comprehensive guide explores the decentralized paradigm of bringing the model to the data, detailing how devices evolve together by sharing abstract mathematical updates. Dive into the 5-step federated architecture loop and discover how cryptographic shields like Secure Aggregation and Differential Privacy prevent data extraction. Learn how advanced algorithms overcome severe bandwidth constraints and hardware disparities to power the next generation of secure, collective AI.
How does a disconnected smartwatch learn your unique music taste offline using just a fraction of the parameters found in massive cloud models? Step inside the mathematical core of on-device training as we decode the micro-weight update. This deep dive breaks down the exact sequence—from the initial Forward Pass and Loss Calculation to local Backpropagation—that enables edge hardware to dynamically adapt its logic in real-time. Discover how this highly targeted learning cleanly bypasses the SRAM memory wall, paving the way for truly autonomous, mathematically private, and incredibly efficient AI across all industries.
.png)