The Hidden Economics of AI: Why Tokens Are Costing Millions in Training and Usage
Vedant Wakchaware
June 18, 2026
•
5 min read
If you use ChatGPT, Claude, or Gemini on a standard $20-a-month subscription, AI feels like a limitless buffet. You type a prompt, you get an answer, and you never see the meter running.
But behind the scenes, every single word you generate is tied to a staggering physical and economic infrastructure. To understand why training frontier models costs hundreds of millions of dollars—and why developers deploying AI agents often suffer massive bills—we have to look at the foundational currency of artificial intelligence: the token.
Here is a breakdown of why processing tokens is so immensely costly, from the initial training runs to the moment an AI agent replies to your prompt.
1. What Exactly is a Token?
AI models do not read text the way humans do. They don't see words; they see data converted into numerical representations called tokens.
The Golden Ratio: In English text, a token is roughly equivalent to 4 characters, or ¾ of a word. The word "hamburger," for example, might be broken into three tokens: "ham", "bur", and "ger".
Beyond Text: Tokens aren't just for words. Images, audio clips, computer code, and even punctuation marks and spaces are converted into visual or audio tokens.
During an AI's training phase, its core task is deceptively simple: look at a sequence of tokens and mathematically predict what the next token should be. But doing this accurately requires an unfathomable scale of data and computing power.
2. The Astronomical Cost of AI Training: A Detailed Breakdown
The cost of training an AI doesn't come from the tokens themselves—which are essentially just fragments of data—but from the physical and human infrastructure required to process trillions of them simultaneously.
When tech CEOs say a frontier model costs $100 million to $200 million (with future models projected to cost billions), that money is going toward a massive, industrial-scale operation. Here is every major expense required to train an AI model:
A. The Compute Bottleneck (Hardware Costs)
Every single time a model processes a token, it performs thousands of complex mathematical operations. Processing 15 trillion tokens requires reading a dataset equivalent to the entire high-quality public internet multiple times over. Standard computers simply cannot handle this.
Specialized GPUs: Tech companies rely on ultra-powerful AI chips, like the NVIDIA H100 or Blackwell GPUs. A single H100 costs around $30,000 to $40,000.
The Cluster: Training a frontier model in a few months requires a cluster of 10,000 to 100,000 GPUs wired together. This means upfront GPU costs alone easily reach hundreds of millions of dollars.
Networking & Storage: GPUs can't work in isolation. They require thousands of miles of expensive fiber-optic cables and specialized networking switches to share data instantly. Add in petabytes of high-speed NVMe storage to hold the training data, and networking/storage can add tens of millions to the hardware bill.
B. Electricity: Powering the Supercomputer
Running a supercomputer with tens of thousands of GPUs at maximum capacity for 3 to 4 months consumes an unfathomable amount of power.
A single NVIDIA H100 GPU draws about 700 watts of power at peak performance. When you cluster 25,000 of them together, plus the servers and network switches housing them, you are looking at a facility drawing a hell amount of electricity.
Training a single leading-edge model can use gigawatt-hours of electricity—as much power as a small town consumes in a year. At commercial industrial electricity rates, the power bill for a single training run easily reaches into the millions of dollars.
C. The Cooling Tax (HVAC, Liquid Cooling, and Water)
Because AI chips draw so much power, they run incredibly hot. If you don't cool them, they melt. Cooling is often one of the most underestimated costs of AI training.
Liquid Cooling Infrastructure: Traditional data center air conditioning is no longer enough for dense AI server racks. Companies must install expensive "direct-to-chip" liquid cooling systems, piping cold coolant directly over the processors.
Chiller Plants & HVAC: To cool the liquid, data centers require massive industrial chiller plants and enormous roof-mounted HVAC systems that draw their own massive amounts of electricity. Often, 30% to 40% of a data center's total electricity bill goes just to running the cooling systems.
Water Consumption: Evaporative cooling systems require millions of gallons of fresh water to keep temperatures down during a months-long training run, adding hefty utility costs and requiring specialized water-treatment infrastructure to prevent mineral buildup.
D. Real Estate and Data Center Construction
You can't just put an AI supercomputer in a standard office building.
Reinforced Infrastructure: AI server racks are incredibly heavy and dense. Companies must buy sprawling plots of land and construct custom-built, reinforced concrete facilities capable of supporting the weight and routing the massive electrical cables and cooling pipes required.
E. Data Acquisition and Human Labor
Scraping the internet is no longer enough. Getting high-quality tokens is incredibly expensive:
Licensing: AI companies pay hundreds of millions of dollars to license highly sought-after, copyrighted data from publishers like The New York Times, Reddit, and academic journals.
Human Annotation (RLHF): To refine the AI so it behaves safely and accurately, companies hire thousands of human experts (doctors, coders, lawyers) to grade and rewrite AI outputs. Generating these specialized, human-verified training tokens can cost upwards of $100 per interaction.
R&D Salaries: The brilliant engineers and researchers architecting these models command some of the highest salaries in the tech industry, adding millions to the project's overhead.
3. The Pricing Paradox: When AI Enters the Real World
Once the model is trained, the cost burden shifts to the developers and companies using it. The moment you move from a flat-fee chat interface to building AI agents or using APIs, the token economy becomes incredibly tangible.
A CEO who recently deployed an AI agent workflow shared a startling reality check:
"I ran a single agent workflow that consumed $12.44 in seven minutes. I’ve run nearly identical workflows for $2... and for $10. Our AI bill was projected to be $76,772.57 this month."
Why does this happen? Success creates exponential costs.
When AI works well, more teams use it, latency expectations drop, and workflows run 24/7. Furthermore, invisible multipliers quietly inflate your token usage. Middle layers—like new IDEs, orchestration layers, agent frameworks, retries, memory logs, and tool calls—sit between you and the model, burning through tokens in the background to ensure the AI functions properly.
4. Understanding Input vs. Output Economics
To survive the token economy, you have to understand how you are being billed. Token-based pricing is straightforward: you pay for what you use. However, not all tokens are created equal.
Input Tokens: These are the prompts, context, and system instructions you send to the AI. Because the model is simply reading and processing this information, they are generally cheaper.
Output Tokens: This is the actual text or data the AI generates in response. Output tokens are typically 3 to 5 times more expensive than input tokens. Generating text is far more computationally heavy, as the model must mathematically predict and produce tokens one by one, demanding complex calculations for every single word it creates.
Most AI providers charge separately for these input and output tokens. The basic formula looks like this:
This seems cheap for a single request. But multiply that by 10,000 daily users, and you’re looking at $110 per day, or $3,300 per month. Scale matters. This means a chatbot generating a 500-word essay consumes far more budget than the brief 10-word prompt used to ask for it.
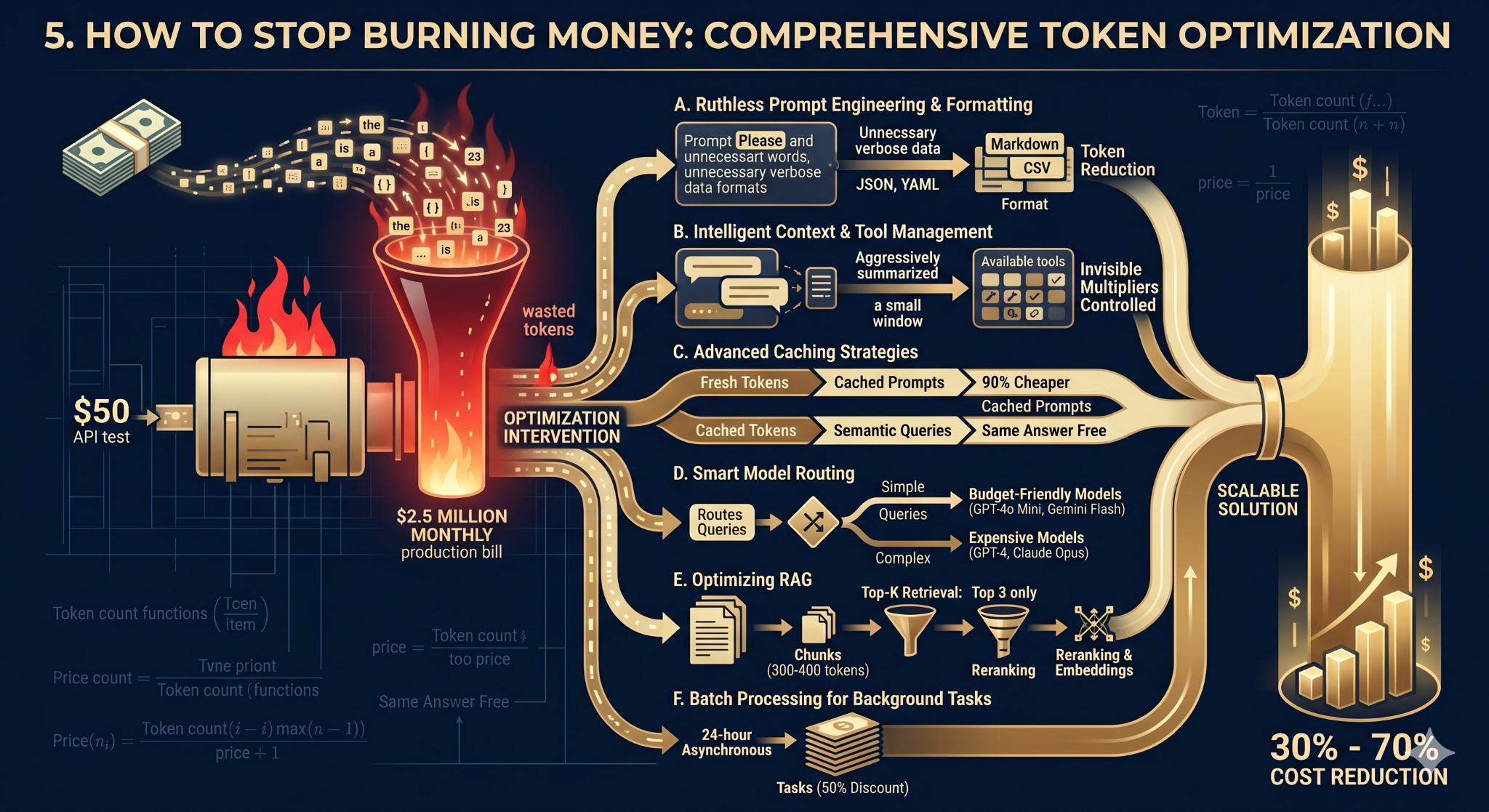
5. How to Stop Burning Money: Comprehensive Token Optimization
If you are building with AI, understanding the underlying economics is the difference between a scalable solution and one that empties out your pocketbook. Scaling an inefficient proof-of-concept can turn a $50 API test into a $2.5 million monthly production bill.
By strategically optimizing your system, you can reduce AI costs by 30% to 70% without sacrificing quality. Here is a detailed breakdown of how to protect your budget:
A. Ruthless Prompt Engineering & Formatting
Every unnecessary word is money leaving your bank account. The way you write prompts and request data dramatically impacts token consumption.
The Politeness Penalty: Being polite in prompts actually increases costs. Research shows non-polite prompts generate fewer tokens per request. Skip the "please," "thank you," and "I would appreciate it if." Give the AI direct, concise commands.
Optimize Data Formats: If you are using the AI to output structured data, do not use JSON if you can avoid it. JSON is highly verbose. Markdown uses roughly 10% fewer tokens than YAML and 34% to 38% fewer tokens than JSON. For tabular data, requesting CSV format outperforms JSON by 40% to 50%. Developers are even creating custom formats like TOON (Token-Oriented Object Notation) to further compress counts.
Enforce Response Length Limits: Because output tokens cost 3 to 5 times more than input tokens, output control is paramount. Set strict maximum response lengths in your system prompts. If you only need a 200-word summary, explicitly tell the model not to exceed that limit.
B. Intelligent Context & Tool Management
Invisible background tokens often consume the bulk of a budget. You must manage what the AI remembers and what it has access to.
Summarize Conversation History: Conversation context grows linearly. A 20-turn chat can easily consume 40,000+ tokens if left unchecked. Do not send the entire conversation history back to the model with every new query. Instead, program your system to send only the last few exchanges, along with a heavily compressed summary of older messages. This can cut context costs by 80% to 90%.
Prune Tool Definitions: If you are building AI agents with access to external tools (APIs, calculators, web search), each tool description adds thousands of tokens to your input context. Do not load all available tools in every request. Dynamically include only the tool definitions that are actually relevant to the immediate task.
C. Advanced Caching Strategies
Why pay the AI to think about an answer it has already figured out?
Prompt Caching: Store frequently used content (like massive system instructions) so the model doesn't have to re-process it from scratch every time. Providers like OpenAI and Anthropic automatically cache prompts over 1,024 tokens. Using a cached prompt is roughly 90% cheaper than reading a fresh input token.
Semantic Caching: This goes a step further by recognizing queries that mean the same thing, even if worded differently. If User A asks, "How do I reset my password?" and User B asks, "What's the process for a password reset?", a semantic cache intercepts User B's query and serves the same pre-generated answer for free. This reduces costs by 10% to 30% in production environments.
D. Smart Model Routing
Not every task needs a highly advanced (and highly expensive) frontier model. Treating every query like a complex math problem is like hiring a surgeon to apply a band-aid.
Implement Dynamic Routing: Route straightforward questions, basic classification tasks, and simple data extraction to budget-friendly models like GPT-4o Mini or Gemini Flash. Reserve the expensive models (like Claude Opus or GPT-4) exclusively for high-level reasoning and complex problem-solving.
The Financial Impact: Smart routing can reduce costs by 40% to 60%. Some companies have cut their per-task AI costs from $0.15 down to $0.054 simply by routing 40% of their daily queries to cheaper models.
E. Optimizing Retrieval-Augmented Generation (RAG)
RAG systems search your company's databases for relevant information and feed it to the AI. If poorly tuned, they pull massive amounts of irrelevant text, wasting thousands of input tokens.
Reduce Chunk Sizes: Break your database documents into smaller pieces (300 to 400 tokens per chunk) rather than massive blocks.
Limit Top-K Retrieval: Only send the top 3 most relevant search results to the LLM, rather than the top 10. You will often maintain 94% of the quality while saving 70% of the token costs.
Implement Reranking: Use a lightweight reranker model to filter out noisy, irrelevant database chunks before they are sent to the expensive LLM. Together, these tweaks can reduce RAG token consumption by up to 91%.
Use Embeddings First: For similarity searches, use embedding models instead of full language models. Embeddings cost a fraction of a cent compared to generative AI.
The Bottom Line
Tokens are the lifeblood of the AI revolution. They are the reason training models rival the cost of space programs, and they are the hidden meters dictating the unit economics of modern software startups. By understanding their scale, their math, and their invisible multipliers, you can harness the power of AI without getting shocked by the bill.
Frequently Asked Questions (FAQs)
What exactly is an AI token? AI models do not read words like humans do; they read numerical representations of data called tokens. In English text, a token is roughly equivalent to 4 characters or ¾ of a word. For example, the word "hamburger" might be split into three tokens: "ham," "bur," and "ger." Tokens can also represent images, audio, code, and even punctuation.
Why does it cost hundreds of millions of dollars to train an AI model? The high cost comes from processing trillions of tokens simultaneously. This requires tens of thousands of specialized, ultra-expensive GPUs (like NVIDIA H100s), massive amounts of electricity and cooling infrastructure, and expensive human labor to curate and grade the data. Furthermore, the mathematical calculations required scale quadratically as the AI processes longer context windows.
Why are output tokens more expensive than input tokens? AI providers typically charge 3 to 5 times more for output tokens (the text the AI generates) than input tokens (your prompt). This is because generating text is computationally heavier. The model has to mathematically predict and produce each token one at a time, whereas it can process your input prompt much more efficiently.
Why is my AI agent or API bill so much higher than expected? If you move from a flat-rate subscription to an API, you pay for every token processed. Costs often inflate due to invisible multipliers in the background. These include system prompts, tool definitions, automatic retries, and constantly resending the entire conversation history back to the model for context.
How can developers and companies reduce their AI token costs? You can cut costs significantly by optimizing how you use AI. Key strategies include:
Model Routing: Use cheaper models (like GPT-4o Mini or Gemini Flash) for simple tasks and save expensive models for complex reasoning.
Prompt Engineering: Remove filler words and polite phrases (like "please" and "thank you"), as they needlessly consume tokens.
While on-device training secures user privacy, it unintentionally traps intelligence, forcing every edge device to learn the exact same lessons from scratch. How do we build a collaborative "hive mind" without exposing raw data to the cloud? The answer is Federated Learning. This comprehensive guide explores the decentralized paradigm of bringing the model to the data, detailing how devices evolve together by sharing abstract mathematical updates. Dive into the 5-step federated architecture loop and discover how cryptographic shields like Secure Aggregation and Differential Privacy prevent data extraction. Learn how advanced algorithms overcome severe bandwidth constraints and hardware disparities to power the next generation of secure, collective AI.
How does a disconnected smartwatch learn your unique music taste offline using just a fraction of the parameters found in massive cloud models? Step inside the mathematical core of on-device training as we decode the micro-weight update. This deep dive breaks down the exact sequence—from the initial Forward Pass and Loss Calculation to local Backpropagation—that enables edge hardware to dynamically adapt its logic in real-time. Discover how this highly targeted learning cleanly bypasses the SRAM memory wall, paving the way for truly autonomous, mathematically private, and incredibly efficient AI across all industries.
Move beyond static AI inference. This comprehensive guide explores the mechanics of continuous on-device AI training, detailing how developers overcome severe hardware and memory bottlenecks. Discover how advanced software optimizations like sparse representations, layer-wise training, and federated learning allow edge devices to adapt, evolve, and learn locally in real-time, completely untethered from the cloud and without compromising user privacy.
.png)