.png)
When we hear the phrase AI training, we immediately picture massive data centers, thousands of GPUs, and models with billions of parameters. However, this cloud-heavy approach doesn't work for edge devices like smartwatches or industrial sensors. These devices face the SRAM Memory Wall—a physical limitation that prevents tiny, battery-powered chips from storing the millions of gradients required to learn new information. This limitation is the central hurdle of the TinyML revolution.
But if a smartwatch can't store millions of parameters, how can it ever learn your unique habits?
The answer lies in rethinking what we actually need to update. On-device training isn't about training a massive brain from scratch; it’s about hyper-targeted, sparse learning. Today, we are going to dive into the mathematical heart of learning—the weight update—and demystify it using a real-world example: an offline, mood-based music playlist that learns your exact taste using just 42 numbers parameters.
To understand why edge learning is so revolutionary, we have to look at how cloud recommenders (like YouTube or massive cloud-based Spotify algorithms) work.
The Cloud Way (Dense Learning): Cloud systems rely on massive embedding tables. They assign every single item (a video or a song) a dense mathematical representation, often 32 to 128 dimensions long. If a catalog has one million songs, the AI is juggling tens of millions of parameters. When you interact with the app, the cloud updates thousands of these parameters. Doing this heavy backpropagation on a tiny edge device would instantly kill its battery and overflow its SRAM.
The Edge Way (Targeted Learning): To bring this intelligence to a disconnected edge device, we have to flip the script. Instead of forcing the device to learn the songs, we only ask it to learn the user.
Imagine a localized playlist app using standard audio features. Every song comes with pre-calculated, fixed data points: Valence (happiness), Energy, Tempo, Acousticness, etc. These describe the songs, and they act as our frozen feature embeddings—we do not train them. The only things that represent the AI's intelligence are a tiny set of parameters mapping how you react to those features.
Through a targeted architecture—often achieved via Knowledge Distillation, where a massive cloud model (the Teacher) distills its core intelligence down into a highly compressed Student model before deployment—a user's entire musical profile can be modeled with just 42 parameters:
This 42-parameter model is the user's digital brain. Now, let’s look at exactly how it learns on a technical level.
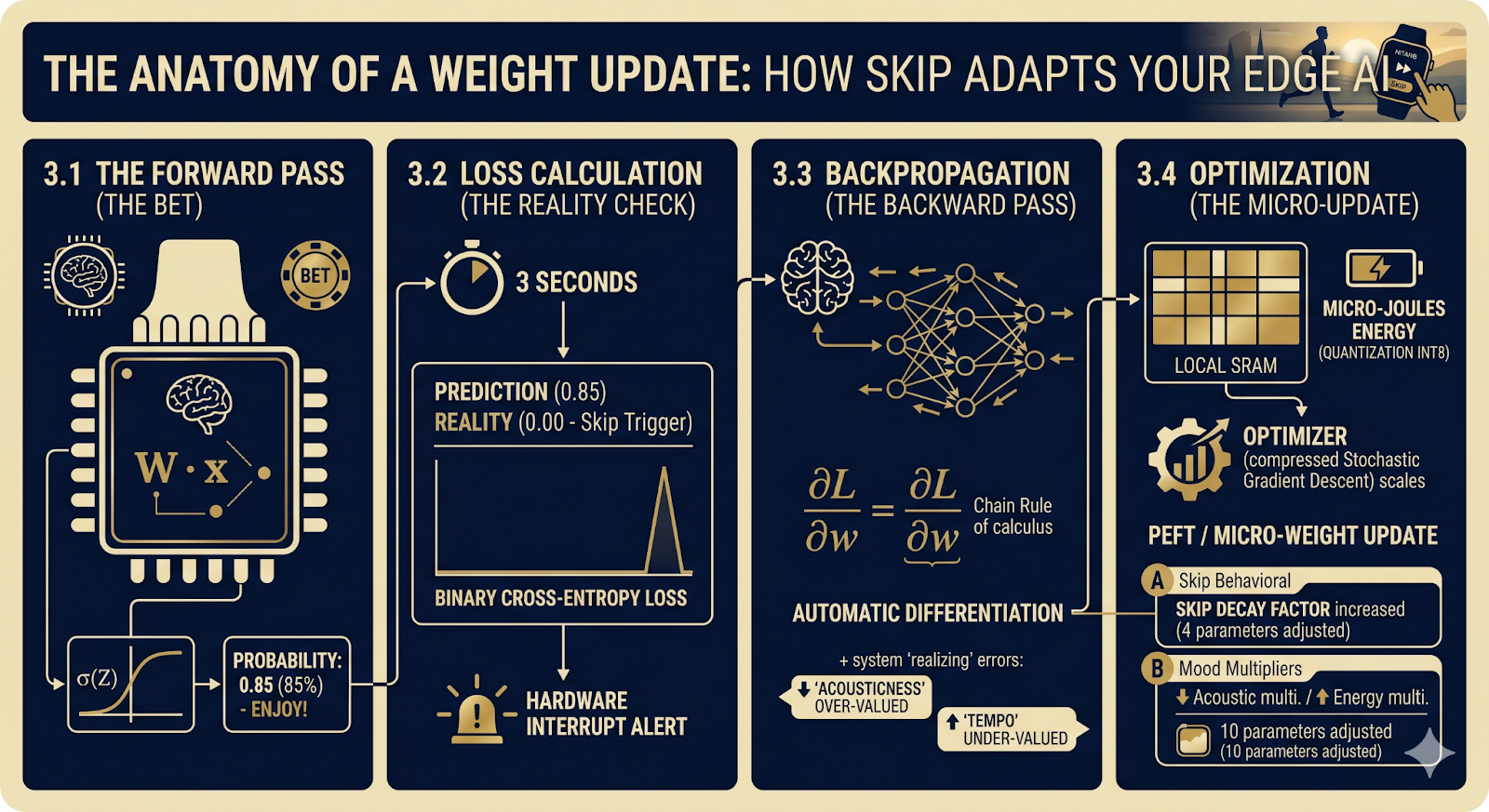
In traditional AI inference, if you skip a song, the app simply moves to the next track. Nothing changes. But in an On-Device Training paradigm, Skip is a crucial mathematical trigger.
Let’s say you are out for a morning run. An acoustic, slow-tempo track comes on, and three seconds later, you hit Skip. To you, it is just a tap on a screen. To the Neural Processing Unit (NPU), it is a catastrophic prediction failure—and it initiates the following sequence:
Before the song even played, the NPU executed a Forward Pass. It performed a rapid series of MAC (Multiply-Accumulate) operations, calculating the dot product of the song's frozen embeddings against your 42 personal weights. Passing this through a sigmoid activation in the scoring layer, the model outputs a high probability score (e.g., 0.85 or 85%)—effectively betting that you would enjoy and complete the track.
Because you skipped the track at three seconds, the ground truth (Reality) immediately drops to 0.0. The system now executes a Loss Calculation, typically using a Binary Cross-Entropy cost function. It mathematically measures the severe penalty of predicting 0.85 when the reality was 0.0. This massive spike in the Loss function acts like a hardware interrupt, signaling to the NPU: Our logic is flawed for this context.
To fix the logic, the device initiates backpropagation. Using the chain rule of calculus, it computes the gradients—the partial derivatives of the Loss with respect to each of your 42 parameters. In cloud AI, backpropagating through billions of parameters requires gigabytes of VRAM to store intermediate activations. But here? The computation graph is incredibly shallow. The NPU traces the error back in microseconds through a process called Automatic Differentiation. It realizes precisely which weights caused the bad bet: an over-valuation of Acousticness and an under-valuation of Tempo for your current high-energy running state.
Finally, a lightweight Optimizer (like a heavily compressed version of Stochastic Gradient Descent) scales these gradients by a specific learning rate and permanently updates the weights in the local SRAM. This process is a pure form of Parameter-Efficient Fine-Tuning (PEFT) acting locally on the edge.
To prevent this math from draining the battery, the NPU leverages Quantization-Aware Training (QAT), allowing it to calculate these precise updates using lower, hardware-friendly precision (like INT8) rather than power-hungry floating-point numbers.
In just a few milliseconds, using micro-joules of battery power, the forward pass, loss calculation, and backpropagation are complete. The device has successfully rewired its own logic without ever connecting to the internet.
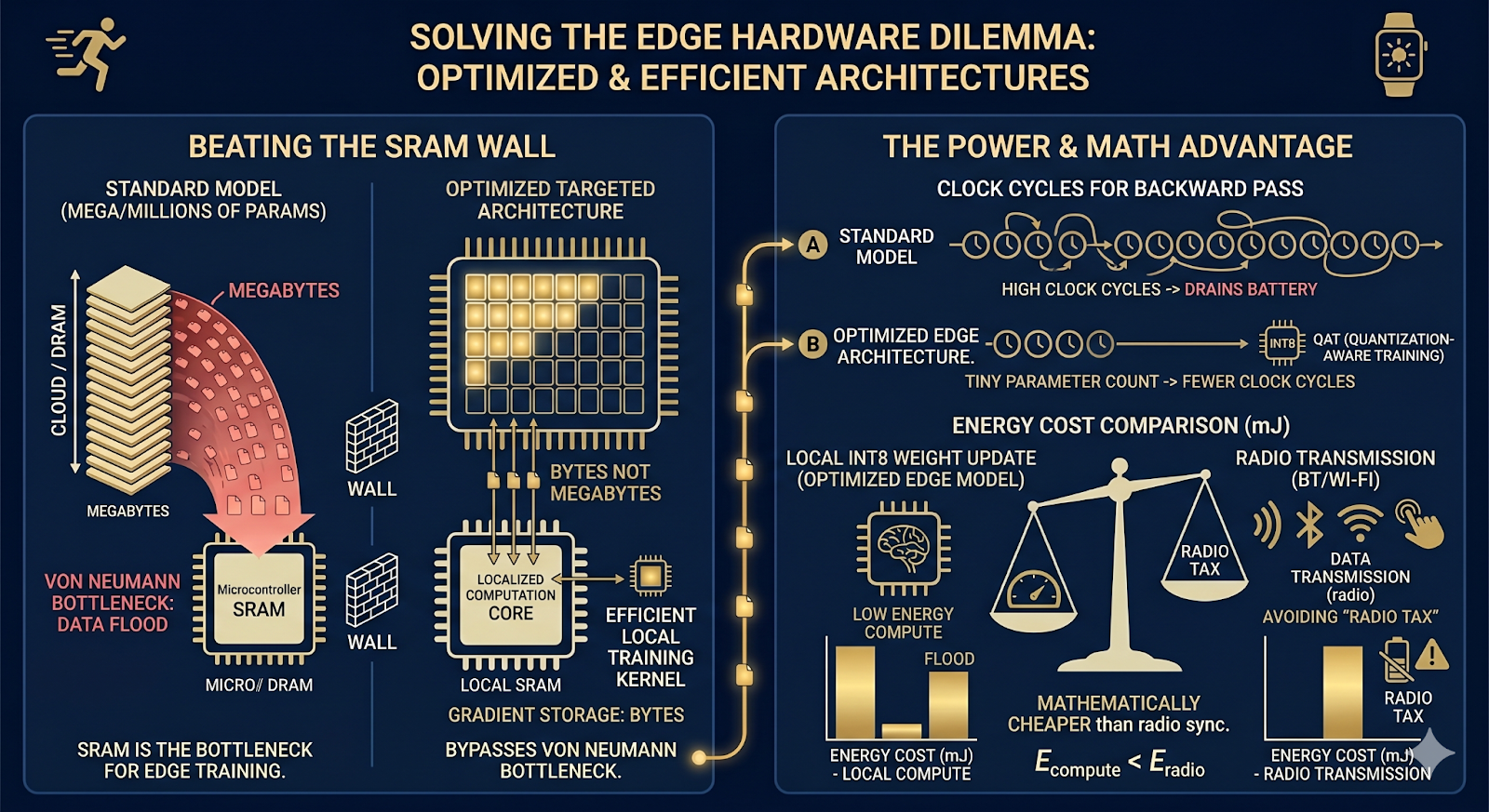
This targeted 42-parameter architecture perfectly illustrates how we overcome the massive technical walls facing edge hardware today.
Beating the SRAM Wall: The biggest bottleneck for edge AI is short-term memory (SRAM), which is needed to store gradients during a backward pass. Because our model only has 42 parameters, storing these gradients requires literally bytes of memory, not megabytes. This cleanly bypasses the Von Neumann bottleneck—the energy-draining physical law of moving massive amounts of data back and forth between memory and the processor.
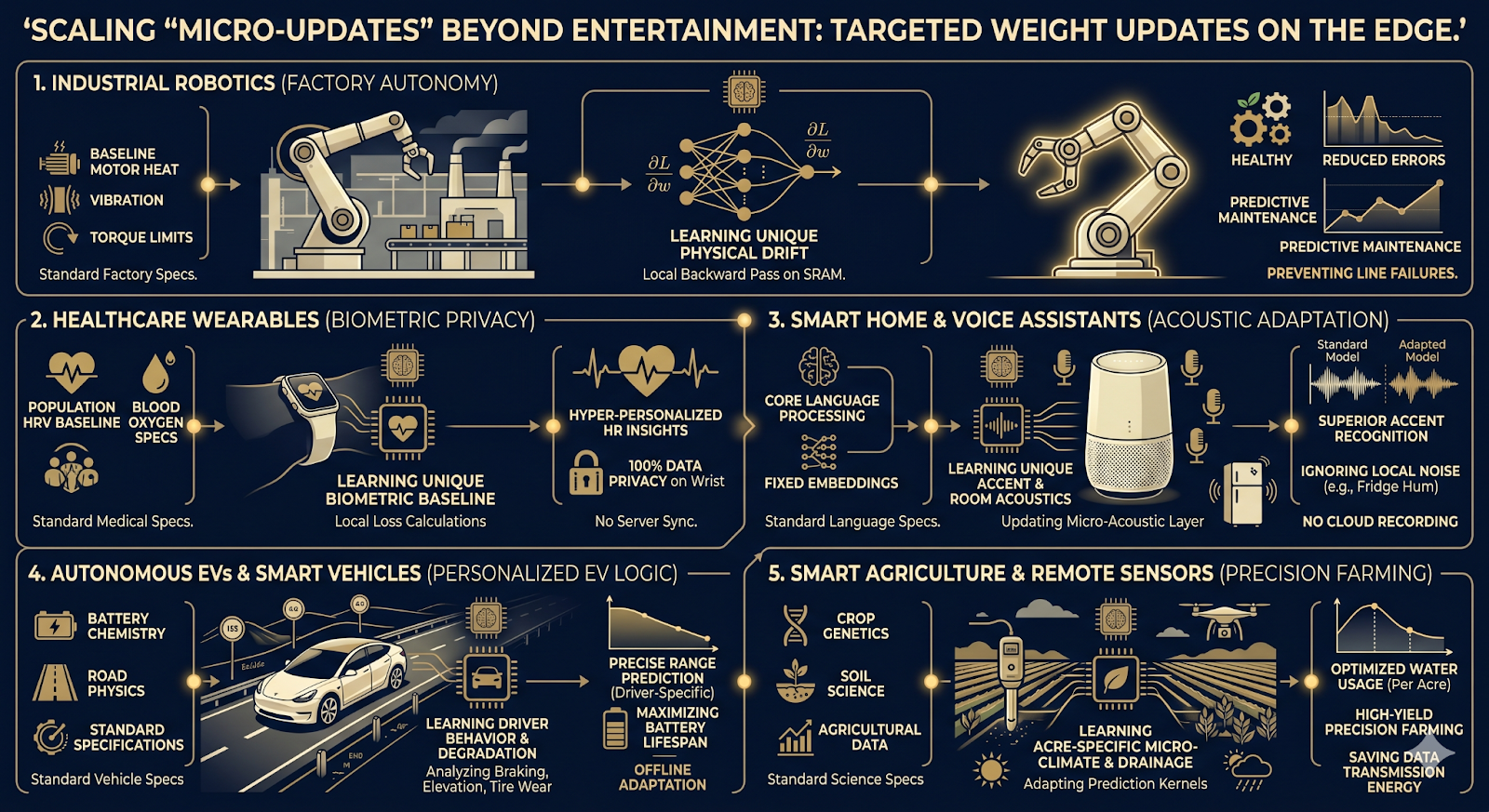
While curating a perfect running playlist is great, the concept of Targeted Weight Updates extends far beyond entertainment. By separating fixed foundational data from highly personalized, trainable weights, we can achieve local autonomy across critical industries:
Once a single device can perform weight updates locally, it unlocks the foundational building block for the most advanced architecture in modern AI: Federated Learning.
How do we take the localized intelligence of one machine and share it globally without compromising data privacy?
Let's scale our industrial robotics example to a fleet of thousands of robotic arms across multiple factories. When individual robots execute their micro-updates to learn a new vibration pattern, they don't share the raw vibration telemetry with the cloud. Instead, they encrypt and transmit only their locally updated gradients using protocols like Secure Aggregation and Differential Privacy.
A central cloud server aggregates thousands of these tiny mathematical updates, averages them out, and sends a refined "Global Baseline" back down to the edge. Through Federated Learning, the entire fleet becomes collectively smarter based on real-world edge friction, but the raw, sensitive data never leaves the individual factory floors.
The era of edge computing is shifting from brute force to elegant precision. As we've seen, true personalized intelligence doesn't necessarily require billion-parameter behemoths.
By isolating the exact weights that matter, limiting the scope of the backward pass, and embracing frameworks like Knowledge Distillation, QAT, and Federated Learning, we bypass the SRAM and battery limitations that have historically kept AI tethered to the cloud. On-device training gives us the ultimate combination: hyper-personalization, offline reliability, and unmatched data security.
The future of AI isn't just happening in giant, remote data centers. It’s happening right in your pocket, calculating micro-updates in real-time.
READ MORE


